


2025 signals a new reality: with almost 90% of organizations using AI, the question isn’t whether to adopt it, it’s how to make it work flawlessly.
Two strategies are leading the way for large language models (LLMs): prompt engineering and fine-tuning. Prompt engineering shapes model outputs by crafting precise, context-rich inputs, using techniques like few-shot prompts and chain-of-thought reasoning. Fine-tuning goes deeper, retraining models on domain-specific data to deliver consistent, reliable results.
In this article, we’ll break down these approaches, compare their strengths, and show how combining them can create smarter, more adaptable AI systems.
Understanding Prompt Engineering
Prompt engineering involves crafting precise, purposeful instructions – called prompts – to shape the responses of large pre-trained AI models. These models have already absorbed vast amounts of language, reasoning patterns, and knowledge from massive datasets, so the quality of their output often hinges more on how prompts are worded than on retraining the model itself.
In simple terms, clearer prompts produce better results. Think of it like ordering coffee from a robot barista: the machine already knows how to make coffee, but the drink you get depends entirely on how specific your order is. A vague request like “I want coffee” may yield something generic, while a detailed instruction such as “Medium cappuccino with oat milk and a caramel shot” produces exactly what you envisioned.
Advanced Prompt Engineering Techniques to Boost LLM Performance
Different tasks call for different prompt strategies to get the best results from large language models. Different tasks require different strategies, and applying prompt engineering best practices can significantly improve how large language models respond.
Here are some widely used advanced techniques:
- Zero-Shot Prompting: The simplest method, where the model relies solely on its pre-trained knowledge to generate a response. For example, asking “Write a poem about the ocean” without any extra context or examples.
- Few-Shot Prompting: The model is provided with a few examples of the desired output, which guide it in following the same style or pattern. Think of it as showing a sample before asking the model to continue in that style.
- Chain-of-Thought Prompting: This approach encourages the model to reason step by step, making it better at handling complex problems. In many applications, these reasoning steps are hidden to keep internal logic private.
- Structured Prompting: By using templates or predefined input formats, this technique ensures outputs are consistent and predictable. It’s especially useful for tasks like data extraction, form completion, or report generation.
- Role-Play Prompting: The model is assigned a specific persona – like a teacher, analyst, customer support agent, or domain expert – to generate context-aware and relevant responses. For example: “You are a ship sailor. Describe your relationship with the ocean in a poem.”
Benefits of Prompt Engineering
Prompt engineering offers several advantages for working with large language models:
- Rapid Experimentation: Prompts can be adjusted and tested instantly, allowing teams to quickly refine tone, style, and accuracy without lengthy processes.
- No Need for Model Retraining: This approach works directly with pre-trained models, eliminating the need to alter or retrain the underlying AI.
- Cost-Effective: By reducing dependence on large datasets and expensive fine-tuning, even small teams can achieve enterprise-level AI performance through well-crafted prompts.
Understanding Fine -Tuning
After exploring prompt engineering, it’s important to understand fine-tuning.
Fine-tuning involves retraining a pre-trained AI model using data from a specific domain so it can excel at specialized tasks. Rather than building a model from scratch, this method starts with a model that already understands general language and adapts it with examples from areas like medicine, finance, or law. This allows the model to grasp domain-specific terminology, patterns, and style, resulting in more precise and relevant outputs.
Since the model already has a foundation in language understanding, fine-tuning focuses on customizing its existing abilities for a particular context. Essentially, it’s a form of transfer learning, where broad knowledge is refined to serve a targeted purpose within AI development services.
You can think of a pre-trained model like a student who has completed general education. Fine-tuning is akin to sending that student through a master’s program in a specialized field, transforming broad understanding into expert-level capability in that area.
Types of Fine – Tuning

Fine-tuning can be broadly classified into two main approaches: full-model fine-tuning and parameter-efficient fine-tuning (PEFT). Each method offers a different mix of control, performance, and resource requirements.
- Full-Model Fine-Tuning: This method retrains all the parameters of a model using domain-specific data, delivering high accuracy and fine-grained control for specialized tasks. However, it demands significant computing power, storage, and time, making it best suited for large-scale projects with ample resources.
- Parameter-Efficient Fine-Tuning (PEFT): PEFT offers a lighter, faster alternative by updating only a small subset of the model’s parameters while leaving the rest intact. Techniques like LoRA or adapter layers act as small modules that the model learns from, enabling it to acquire new, task-specific skills without the heavy computational load of full retraining. PEFT saves time, memory, and cost, making it ideal for teams seeking strong results without extensive technical resources.
Benefits of Fine-Tuning
Fine-tuning offers several advantages for adapting AI models to specialized tasks:
- Domain Specialization: Fine-tuned models grasp the specific terminology, patterns, and style of a particular industry. Whether the data comes from medical records, legal documents, or financial reports, the model aligns closely with the language and context of that domain.
- Consistent Performance: Trained on carefully curated, high-quality data, fine-tuned models deliver stable and reliable outputs. This reliability is critical in high-stakes or compliance-sensitive applications.
- Improved Accuracy: Learning directly from domain-specific data enhances the model’s precision and contextual understanding. It also reduces sensitivity to how prompts are phrased, making the model more dependable for specialized tasks.
Prompt Engineering vs. Fine -Tuning: A Comparison
We’ve covered the basics of prompt engineering and fine-tuning, including their methods and benefits. Both techniques enhance AI model performance, but they differ significantly in approach, cost, and application. The table below highlights the key distinctions between the two, helping you understand when to use each method effectively.
When to Opt for Prompt Engineering
Let’s explore the scenarios where prompt engineering is the ideal choice.
Prompt engineering is most effective when speed, adaptability, and creativity take precedence over absolute precision. It’s particularly valuable for teams that want to experiment with large language models (LLMs) without relying on massive datasets or complex infrastructure.
Applying prompt engineering best practices helps ensure more consistent and meaningful outputs, even in fast-moving or uncertain environments.
Situations where prompt engineering shines include:
- Experimentation: It allows you to quickly test how a model handles new or changing tasks without going through lengthy training cycles.
- Limited Resources: When domain-specific data is scarce or computing power is limited, prompt engineering can still deliver strong results without additional training.
- General Tasks: For routine activities like summarizing text, brainstorming ideas, or drafting basic content, well-crafted prompts are often sufficient since perfect accuracy isn’t always critical.
Recent studies support this approach. A 2025 analysis of real-world LLM applications found that refining prompts, trying different strategies, and providing clearer instructions significantly enhance output quality. Techniques such as role prompting, chain-of-thought prompting, and contextual additions consistently lead to more precise and useful responses.
When to Choose Fine -Tuning
Fine-tuning becomes the preferred approach when precision and domain expertise outweigh the need for speed. By retraining a model on specific datasets, it learns the context, jargon, and subtleties necessary for high-stakes applications.
Ideal scenarios for fine-tuning include:
- Specialized Fields: Critical industries like healthcare, law, or finance benefit from fine-tuned models that require expert-level accuracy and understanding.
- Repetitive or Large-Scale Tasks: Fine-tuning ensures consistent and reliable outputs across workflows that are repetitive or involve large volumes of data.
- Proprietary Data: Organizations can train models on sensitive internal datasets while retaining full control and safeguarding privacy.
- Brand and Tone Consistency: When uniform messaging is crucial – such as in customer support, compliance documentation, or large-scale content creation – fine-tuning helps maintain a consistent voice and standard.
A practical example comes from Automatic Speech Recognition (ASR) systems. Researchers fine-tuned an existing ASR model using real-world radio communication recordings from ships. These recordings were noisy and filled with maritime-specific terminology, posing challenges for standard ASR models. After fine-tuning, the model achieved significantly higher accuracy, demonstrating the advantage of domain-specific training.
Prompt Engineering vs. Fine -Tuning: Challenges and Trade-Offs
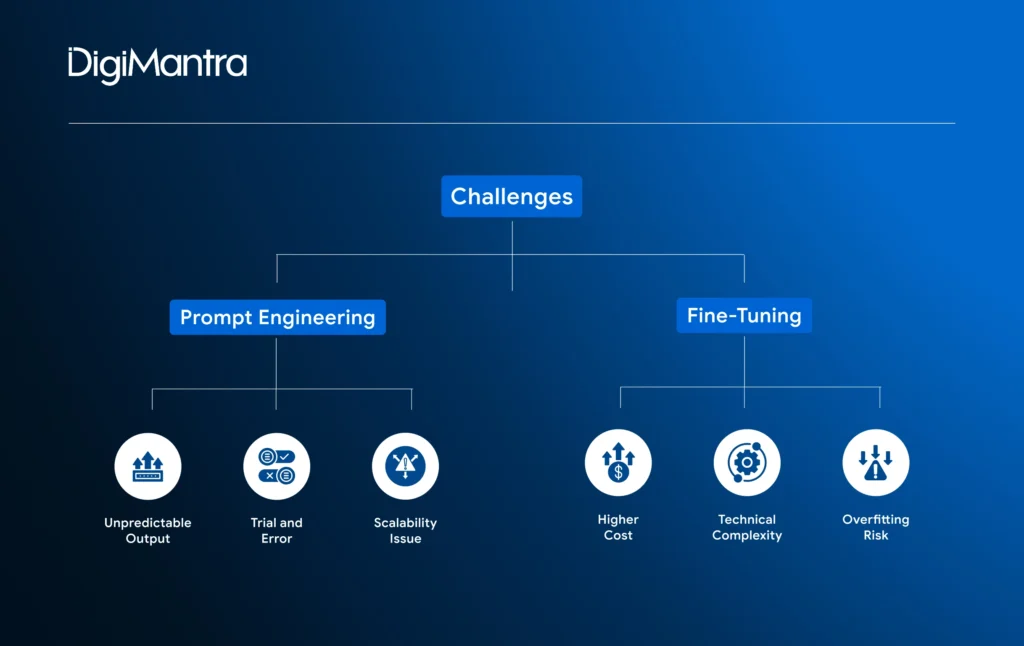
Both fine-tuning and prompt engineering can significantly enhance AI model performance, but each comes with its own set of limitations. Understanding these trade-offs helps teams select the approach that best aligns with their objectives.
Common challenges with prompt engineering:
- Unpredictable Outputs: Minor tweaks in phrasing can produce drastically different results, making prompt-based approaches sometimes inconsistent.
- Trial-and-Error: Crafting the ideal prompt often requires repeated experimentation, which can be time-consuming.
- Scalability Issues: Managing hundreds or thousands of prompts across workflows can be difficult and hard to standardize.
Challenges to consider with fine-tuning:
- Higher Costs: Fine-tuning demands substantial computational resources and high-quality labeled data, which can drive up expenses.
- Technical Complexity: Deploying fine-tuned models involves setting up GPUs, building data pipelines, and managing intricate workflows.
- Overfitting Risks: Without careful management, a fine-tuned model may excel on its training data but struggle with new or unseen inputs.
In essence, prompt engineering delivers speed and flexibility, while fine-tuning provides greater accuracy and control but typically requires more time, data, and resources. Deciding between the two, or combining both, depends on your specific needs. A trusted digital transformation company helps you easily navigate this decision. From high-quality data annotation and collection to custom generative AI and LLM solutions, it guides you through training, deployment, and optimization.
How a Hybrid Approach Boosts AI Performance
We’ve looked at prompt engineering and fine-tuning as separate strategies for maximizing AI capabilities. But what if we combine the two?
Integrating fine-tuning with advanced prompting techniques can unlock a higher level of AI intelligence. In this approach, fine-tuning equips the model with deep domain knowledge, while prompt engineering shapes how that knowledge is applied in specific contexts.
A state-of-the-art AI Research and many industry experiences reveal that this hybrid strategy often outperforms using either method alone. Many modern LLM development workflows follow this pattern: the model is first fine-tuned on domain-specific data to build expertise, and then its performance is enhanced through iterative prompt refinement.
This cyclical process improves both the model’s reasoning and its ability to produce accurate, context-aware outputs. Fine-tuning adds depth, and prompt engineering provides precision – together creating a more versatile, high-performing AI system.
The Takeaway

Understanding LLM fine-tuning vs. prompt engineering makes it clear how both strategies can work together rather than compete. Prompt engineering shapes the model’s responses through clear, context-rich instructions, while fine-tuning equips it with in-depth knowledge and understanding of specialized domains. When combined, they create AI that is both flexible and precise – one driving creativity, the other ensuring accuracy and reliability.
At DigiMantra, we help organizations achieve this balance. By blending the strategy of smart prompting with the precision of fine-tuning, we develop AI systems that are faster, more intelligent, and closely aligned with your business objectives. Connect with us to bring your next AI model to life.

AI-FIRST ENGINEERING FOR MODERN BUSINESSES
Designed for performance. Powered by innovation.
 Product Development
Product Development- Custom Software
 Mobile & Web
Mobile & Web
- AI & Automation
- Cloud Management
- Intelligent Systems