


We’re now entering what Microsoft Research refers to as the breaking of the AI “data wall” – a moment when many organizations have tapped out their supply of clean, reliable, and ethically collected data for training advanced machine learning models. The emerging answer to this limitation is simple yet transformative: generate the data instead of sourcing it.
Synthetic data generation is becoming a foundational asset across machine learning, deep learning, generative AI (GenAI), LLM development, and analytics workflows. Industry forecasts reinforce this shift.
Gartner predicts that by 2030, synthetic datasets will surpass real-world data in AI model training. Yet for many business leaders, the idea of artificial data replacing real data still feels unfamiliar. But the momentum is undeniable.
By 2028, an estimated 80% of AI model training data is expected to be synthetic – up from just around 5% a few years ago. This dramatic rise signals not a temporary trend, but a complete rethinking of how data is created, governed, and scaled.
In this guide, we break down what synthetic data is, how it is created, its types, key benefits, limitations, real-world use cases, and best practices, helping you understand where it fits in the modern AI development strategy.
What Is Synthetic Data?
Synthetic data refers to information generated by algorithms rather than gathered from real-world events or user interactions. Instead of relying on naturally occurring datasets, organizations use artificially created data to train and validate machine learning models, test software, or run complex simulations.
Its value becomes especially evident when real data is scarce, sensitive, or expensive to collect. Since synthetic data generation happens without tying back to actual individuals, it avoids exposing personally identifiable information (PII). This built-in privacy benefit also allows teams to create more balanced, diverse datasets by reducing bias and improving the performance and fairness of AI systems.
Imagine training a computer vision model for life on Mars. Real images from missions like Spirit and Opportunity can help, but they’re far too limited. Synthetic images fill that gap, creating a broader, more diverse dataset when real-world examples simply don’t exist.
The visual above highlights why synthetic data is important when actual data is limited or unavailable.
Synthetic data generation also allows teams to build controlled, repeatable scenarios.
For example, an autonomous vehicle company worried about foggy conditions doesn’t need thousands of real foggy-road recordings; they can generate realistic simulations to train the model safely and at scale.
Above: A realistic fog-covered street scene provides valuable training data for autonomous vehicles, without requiring real-world capture.
The same need applies to generative AI and LLMs. Even with the vast amount of content online, many topics remain underrepresented. As Elon Musk noted, we’re reaching the limits of available human-generated data. While the statement may be exaggerated, it underscores a real shift: AI systems increasingly depend on high-quality synthetic data to keep improving.
How Is Synthetic Data Created?
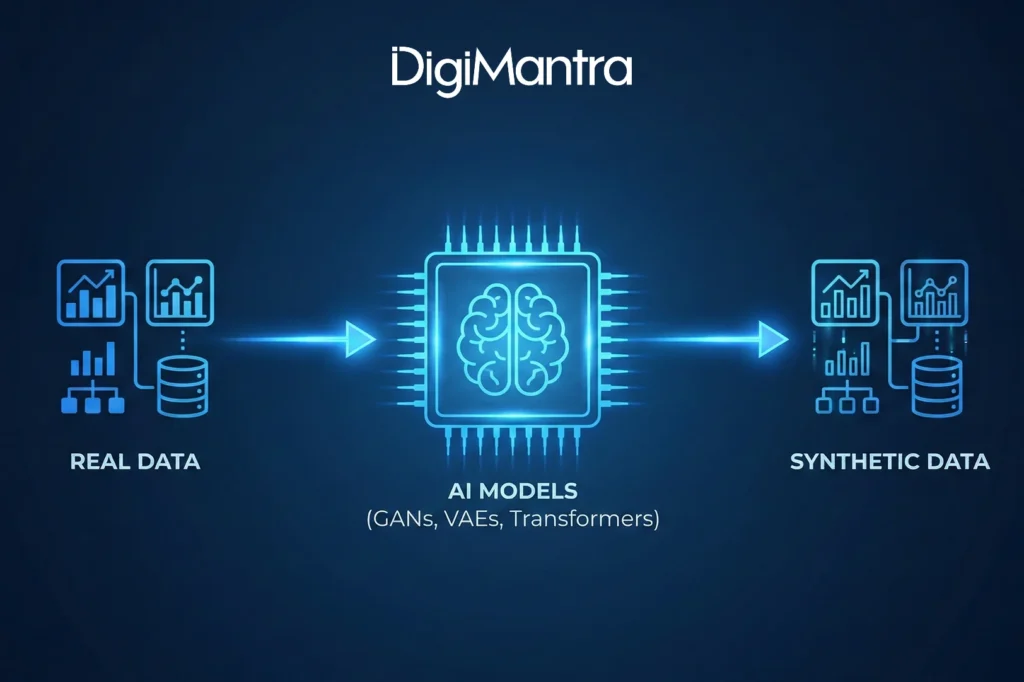
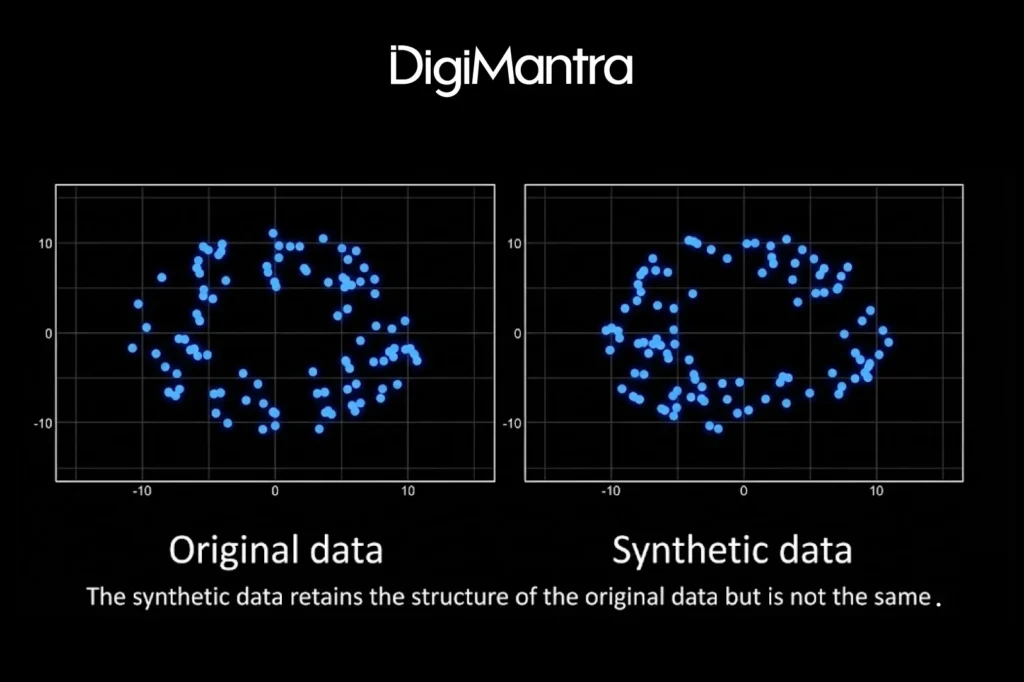
Synthetic data generation occurs in several ways, but one of the most powerful and widely used approaches involves AI models trained on real-world datasets. Using deep learning techniques such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformers(advanced NLP/vision), these models learn the underlying patterns, relationships, and structures within the original data. Once trained, they can produce entirely new data points that mirror those patterns, resulting in datasets that look and behave like the real thing. The figure below illustrates this structural similarity.
Another technique relies on computer algorithms that simulate how real data behaves. These AI and machine learning models recreate the statistical properties such as distribution, variation, and correlations found in actual datasets.
Synthetic data generation also happens through simpler methods, such as random number generation. While this type of data is uniform and uncorrelated, it’s useful for testing systems where realism is less important than volume or diversity.
Together, these synthetic data generation methods allow teams to generate safe, scalable, and customizable data tailored to their needs.
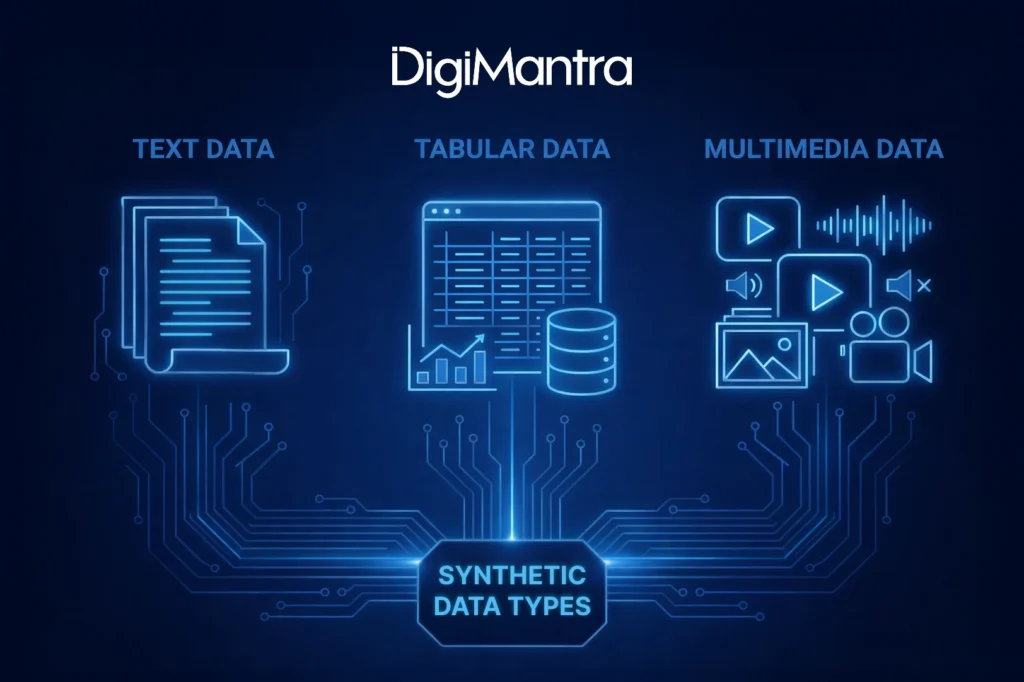
Types of Synthetic Data
Synthetic data can appear in multiple formats: tabular, text-based, or multimedia.
Text data supports NLP tasks such as classification, summarization, and intent detection.
Tabular data helps create synthetic versions of relational databases for analytics and modeling.
Multimedia data (images, videos, audio, and other unstructured formats) is widely used in computer vision for tasks like classification, detection, and recognition.
Beyond format, synthetic data is also categorized by how closely it relies on real-world information:
Fully Synthetic Data
Fully synthetic data generation happens entirely by algorithms and contains no direct traces of real-world records. Machine learning models learn the patterns and statistical relationships in the original dataset and then create completely new samples that mimic those characteristics.
For example, a financial institution may not have enough examples of fraudulent behavior. Fully synthetic datasets can simulate suspicious transactions to strengthen fraud-detection models without exposing real customer data.
Partially Synthetic Data
Partially synthetic data generation starts with real data but replaces selected attributes, especially sensitive ones, with artificially generated values. This approach maintains the usefulness and structure of the original dataset while protecting sensitive details.
In healthcare or clinical research, this method allows researchers to analyze realistic patient trends without revealing personal identifiers or confidential medical information.
Hybrid Synthetic Data
Hybrid data blends elements of both real and synthetic datasets. Real records are combined or paired with generated ones to form a mixed dataset that preserves the richness of original data while ensuring privacy.
For instance, businesses can use hybrid synthetic data to study customer behavior patterns without linking insights back to any identifiable individual.
This classification gives organizations the flexibility to choose the right balance between realism, privacy, and control for their AI applications.
Why is Synthetic Data a Game Changer for AI Development?
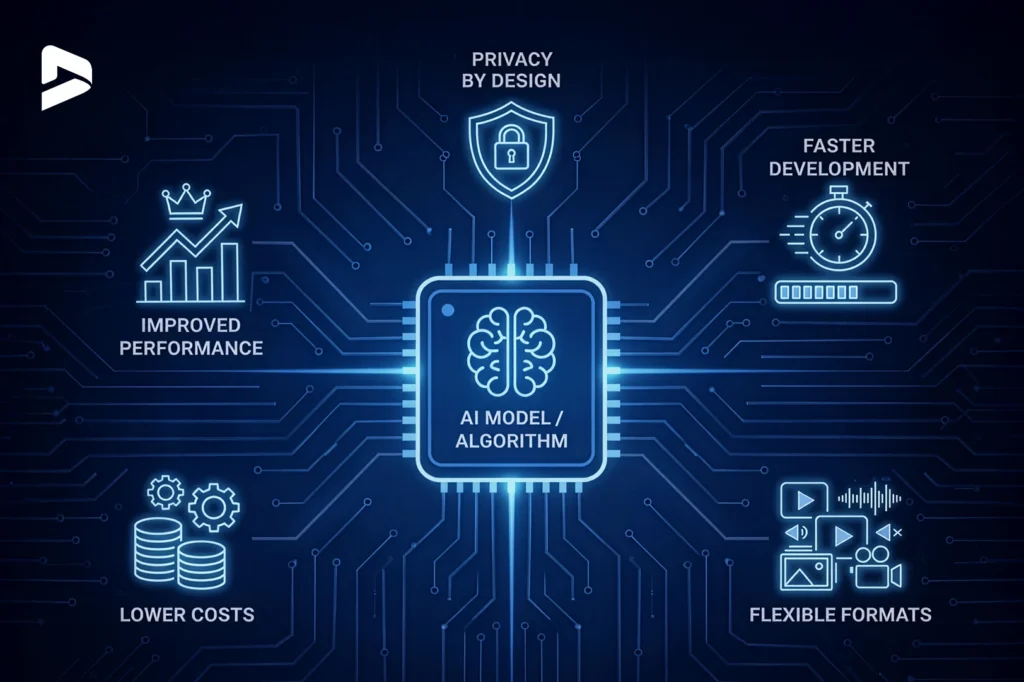
Synthetic data isn’t just a substitute for real data; it’s becoming a strategic advantage for organizations building AI at scale. It accelerates development, reduces dependency on sensitive information, and enables experimentation that would otherwise be costly or impossible. As the technology evolves, its benefits are becoming even more transformative.
Lower costs: Synthetic data generation is far more affordable than collecting, cleaning, and labeling real-world datasets.
Faster development cycles: Synthetic datasets can be generated instantly to match specific use cases or edge scenarios.
Privacy by design: Since synthetic data generation doesn’t contain actual personal information, it avoids GDPR complexities.
Improved performance with limited real data: In highly regulated sectors such as healthcare or finance, where real data is restricted or scarce, synthetic data strengthens model accuracy and resilience, even for rare or unusual events.
Flexible formats: Modern synthetic data generation tools can produce everything from structured tabular data to images, audio files, and sensor readings. This versatility supports a wide range of AI systems and unlocks scalable, multi-format innovation.
Challenges of Synthetic Data
While synthetic data offers significant advantages, it also comes with limitations that organizations must manage carefully. Following strong governance and generation practices helps minimize these risks and ensures the synthetic data generation remains useful and trustworthy.
Below are some key challenges:
Bias
Synthetic data can unintentionally carry over the biases present in the real datasets used to train generative models. If the original data lacks representation across regions, demographics, or behaviors, those gaps may persist or even amplify. Using diverse, well-balanced source data and incorporating multiple data streams can help reduce these issues.
Model Collapse
Model collapse occurs when AI systems are trained repeatedly on synthetic data instead of real-world information. Over time, the model begins to drift, lose accuracy, and generate lower-quality outputs. Maintaining a healthy blend of real and synthetic data, and refreshing training data regularly, helps prevent this degradation.
Accuracy vs. Privacy Trade-off
Achieving strong privacy often requires altering or removing sensitive details from synthetic datasets. But heavy modifications can reduce realism, impacting model performance. Finding the right balance between data utility and privacy protection is an ongoing challenge.
Verification
Validating synthetic data is essential. Teams must confirm that the generated data closely matches the statistical properties of real datasets without leaking sensitive information. This requires rigorous testing, benchmarking, and continuous monitoring.
By understanding these challenges, organizations can design safer, more reliable workflows that maximize the value of synthetic data while minimizing risk.
Synthetic Data Use Cases
Synthetic data is highly adaptable and can be created for countless real-world applications. Below are some industries where it delivers significant value:
Automotive
Synthetic data enables automakers and mobility companies to simulate complex road environments, traffic patterns, and rare driving scenarios.
- Agent-based machine learning models help study traffic flow and optimize transportation systems.
- Car manufacturers can reduce the cost and effort of collecting real crash data by generating realistic crash simulations.
- Autonomous vehicle developers rely heavily on synthetic images, sensor readings, and edge-case scenarios to safely train self-driving systems without risking real-world experimentation.
Image source: Computer vision | Keylabs
Finance
Financial institutions use synthetic data generation to model risk, build predictive systems, and test algorithms without exposing sensitive customer information.
Examples include:
- Simulated credit card activity can be used to strengthen fraud-detection machine learning models.
- Artificial banking transactions help train systems for anti-money laundering.
- Synthetic claim and policy datasets support more advanced analytics in the insurance sector.
These datasets allow teams to experiment freely while staying compliant with strict privacy regulations.
Healthcare
In healthcare and life sciences, synthetic data generation helps accelerate research while protecting patient confidentiality.
- Pharmaceutical companies use synthetic data to speed up early drug discovery and testing.
- Researchers apply partially synthetic datasets in clinical trials to maintain statistical integrity while safeguarding personal health information.
- Fully synthetic patient records, medical images, and diagnostic data support the development of new treatments and AI-driven diagnostic tools.
- Epidemiologists use agent-based simulations to study how diseases spread and evaluate potential interventions.
Manufacturing
Manufacturers leverage synthetic data to improve product quality, boost efficiency, and reduce downtime.
- Computer vision models gain better accuracy in visual inspection when trained on synthetic images of defects that rarely appear in real datasets.
- Synthetic sensor data strengthens predictive maintenance models, helping companies anticipate equipment failures before they occur.
- Simulated production-line data aids in optimizing workflows and reducing operational risks.
Retail
Retail businesses apply synthetic data to gain deeper insights into customer behavior and improve decision-making without relying exclusively on sensitive consumer data.
- Generated shopping patterns and customer journeys help power recommendation engines and personalization models while preserving privacy.
- Retailers simulate demand fluctuations to refine inventory planning, pricing strategies, and supply chain operations.
- Synthetic images support computer vision use cases such as shelf monitoring, product recognition, and checkout automation by mimicking different store environments and conditions.
- Artificial transactions and POS data also enable safer testing of promotions, loyalty programs, and fraud prevention systems.
Cybersecurity
In cybersecurity, synthetic data is critical for preparing defenses against threats that are rare, unpredictable, or unsafe to reproduce in live systems.
- Security teams generate artificial network traffic, access logs, and behavioral data to train anomaly and intrusion detection models.
- Simulated cyberattacks – including phishing, malware activity, and insider threats – allow organizations to test security controls without endangering real infrastructure.
- Synthetic datasets also support security simulations and incident response training, helping teams strengthen resilience against emerging and zero-day threats.
- By using synthetic data, organizations can continuously improve security models while meeting compliance and data protection requirements.
Across these sectors, synthetic data unlocks faster innovation, greater privacy, and safer experimentation, making it an essential tool for modern AI development.
Getting Started with Synthetic Data
Adopting synthetic data generation has never been more accessible, thanks to a rapidly expanding ecosystem of tools, libraries, and open resources.
For Python developers, libraries such as SDV, Faker, and data-synthetic provide flexible options for generating structured datasets. R users can turn to Synthpop for statistically robust synthetic data generation. When it comes to producing visual or simulation-heavy datasets, platforms like Unity, Unreal Engine, and CARLA are widely used for building realistic virtual environments.
You can also accelerate learning with open-source synthetic datasets and demos. Resources like Synapse, COCO-Synth, and AirSim offer ready-to-use examples, and community tutorials help you experiment without starting from scratch.
As you begin, keep a few best practices in mind:
- Generate synthetic data with a clear understanding of the task or problem you’re solving.
- Combine synthetic and real data when possible to improve balance and realism.
- Validate your datasets thoroughly to ensure the machine learning models trained on them perform reliably in real-world scenarios.
Starting small and iterating quickly with the help of a trusted digital transformation company will help you unlock the full potential of synthetic data in your AI workflows.
The Synthetic Future Starts Now
Synthetic data has become a cornerstone of modern AI development, enabling faster model iteration, large-scale testing, and innovation without compromising privacy. As we move toward 2030, the line between “real” and “synthetic” data will continue to fade. What truly matters is whether the data, regardless of its origin, can train AI systems that perform reliably in real-world environments.
Synthetic data generation is no longer an emerging trend; it has already gone mainstream. The real question now is whether your data infrastructure is equipped to harness its full potential. With evolving data regulations and the rising demand for high-quality training datasets, this is the ideal moment to invest in synthetic approaches.
Importantly, synthetic data isn’t designed to replace real-world data; it exists to strengthen it. By filling gaps, reducing bias, and enriching datasets with edge cases that are difficult or impossible to capture naturally, it enhances both model performance and fairness. As tools mature and adoption accelerates across industries, synthetic data is proving to be one of the most powerful accelerators of AI capability.
In many ways, the future of AI is already here – and it’s synthetic. Contact us today to discover practical ways to adopt synthetic data across your operations.
FAQs
1. Is synthetic data for AI training worth it, or just hype?
Synthetic data is worth it when used correctly. It helps overcome data shortages, protects privacy, and allows AI models to learn from rare or risky scenarios. While it can’t fully replace real-world data, combining synthetic and real data leads to faster training, better coverage, and more reliable AI systems.
2. How does synthetic data work?
Synthetic data is worth it when used correctly. It helps overcome data shortages, protects privacy, and allows AI models to learn from rare or risky scenarios. While it can’t fully replace real-world data, combining synthetic and real data leads to faster training, better coverage, and more reliable AI systems.
3. How does synthetic data benefit an AI model?
Synthetic data helps AI models learn faster and more reliably by providing large, diverse datasets without privacy risks. It fills gaps in real data, introduces rare or edge-case scenarios, and reduces bias caused by limited samples. When combined with real-world data, it improves model accuracy, robustness, and overall performance.
4. What’s the real-world difference between AI trained on synthetic data vs. real user data?
AI trained on real user data reflects true behavior and real conditions, while synthetic data expands coverage by adding scale, privacy safety, and rare scenarios. The strongest AI models combine both, using real data for authenticity and synthetic data for completeness and resilience.
5. What’s the difference between synthetic data and fake data?
Synthetic data is intentionally generated to reflect real-world patterns and is used for AI training and testing. Fake data is random or misleading and doesn’t represent real behavior, making it unreliable for AI use.


AI-FIRST ENGINEERING FOR MODERN BUSINESSES
Designed for performance. Powered by innovation.
 Product Development
Product Development- Custom Software
 Mobile & Web
Mobile & Web
- AI & Automation
- Cloud Management
- Intelligent Systems